
Most high end platforms for high performance computing are equipped with multi-core CPUs. In order to fully utilize the CPUs multiple jobs must be run on each platform or the code must be changed to utilize multiple CPUs. There are several methods used to take advantage of multiple CPUs; OpenMP, MPI, MPICH etc. The simpler approaches utilize one server and all its CPUs in a shared memory model, the more complex approach is to split the code accross several servers with a master process handling communication between the shared memories and aggragating the results. Either way, well written code split accross multiple CPUs can generally increase job efficiency.
There are obviously several caveats; some code cannot be 'parallelized' due to the nature of the algorithm, the code should be correctly optimized, disk IO should be reduced and in the shared memory model network latency can become a significant delaying factor.
Below is a graph of job completion times, where a lower (faster) result is better. The first bar is the time for the job to complete using only one processor. This is a simple array calculation compiled in C++ running on a BL460 blade with dual quad cores. The single CPU iterative job completes in 20 seconds. Next the code is compiled with the omp.h library allowing it to parallelize the array calculation loops. Unexpectedly the time to complete is longer than the iterative job. This is because the job was only allowed to run on one core. The overhead of the omp library managing multi-threading in the core is what caused the increase in run-time.
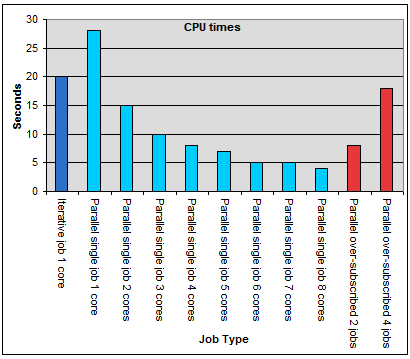 By increasing the number cores on which the job is allowed to run we see
an immediate increase in speed and reduction of job time. This is
unfortunately not a linear improvement due to communication latency, in this case in the processor cache.
OMP allows more threads to run than there are physical cores which is
fine for the purpose of testing. Additionally one can run more than one
multi-threaded job per server. These practices however should be
avoided as they cause processor contention as the tasks are switched in
and out of CPU context. This behaviour is clearly seen in the last two
job runs.
By increasing the number cores on which the job is allowed to run we see
an immediate increase in speed and reduction of job time. This is
unfortunately not a linear improvement due to communication latency, in this case in the processor cache.
OMP allows more threads to run than there are physical cores which is
fine for the purpose of testing. Additionally one can run more than one
multi-threaded job per server. These practices however should be
avoided as they cause processor contention as the tasks are switched in
and out of CPU context. This behaviour is clearly seen in the last two
job runs.
By increasing the number cores on which the job is allowed to run we see
an immediate increase in speed and reduction of job time. This is
unfortunately not a linear improvement due to communication latency, in this case in the processor cache.
OMP allows more threads to run than there are physical cores which is
fine for the purpose of testing. Additionally one can run more than one
multi-threaded job per server. These practices however should be
avoided as they cause processor contention as the tasks are switched in
and out of CPU context. This behaviour is clearly seen in the last two
job runs.