
Two new servers have been added to the cluster bringing the core count to 20.
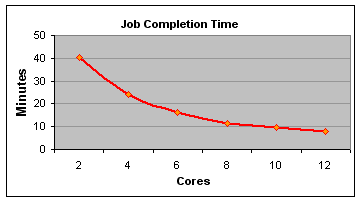
Below is a set of simple tests carried out with a C program compiled with mpicc which runs a large number of floating point computations on a matrix. The speed improvement over greater numbers of cores is gratifying, but not linear due to threadRAM communication latency as well as the fact that a mixed architecture is being used. Node 300 has 1.6 GHz cores as opposed to the 3.6 GHz cores of the 200 series.
 Another disadvantage of having a mixed environment is that cores that complete early are still assigned to a job via the scheduling system and are not released until the entire job completes, making them temporarily unavailable to other users. The solution will be to partition the 200, 300 and 400 series of worker nodes.
Another disadvantage of having a mixed environment is that cores that complete early are still assigned to a job via the scheduling system and are not released until the entire job completes, making them temporarily unavailable to other users. The solution will be to partition the 200, 300 and 400 series of worker nodes.
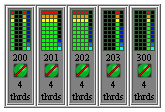 A potential problem due to potential mis-use through lack of understanding of the scheduling system can be seen. Here the submitted job has reserved 4 cores on each node yet it only runs 4 threads in total. The PBS reservation directive should closely match the mpirun arguments and machine file parameters. Here mpirun has been called with the argument "-np 4", while the PBS directive "-l nodes=srvslnhpc200:ppn=4+ srvslnhpc201:ppn=4+ srvslnhpc400:ppn=4" reserves a total of 12 cores. This is wasteful as it blocks other users from submitting jobs to idle cores. In the above example nodes 201 and 202 were not considered as they were running a separate job.
A potential problem due to potential mis-use through lack of understanding of the scheduling system can be seen. Here the submitted job has reserved 4 cores on each node yet it only runs 4 threads in total. The PBS reservation directive should closely match the mpirun arguments and machine file parameters. Here mpirun has been called with the argument "-np 4", while the PBS directive "-l nodes=srvslnhpc200:ppn=4+ srvslnhpc201:ppn=4+ srvslnhpc400:ppn=4" reserves a total of 12 cores. This is wasteful as it blocks other users from submitting jobs to idle cores. In the above example nodes 201 and 202 were not considered as they were running a separate job.
Another disadvantage of having a mixed environment is that cores that complete early are still assigned to a job via the scheduling system and are not released until the entire job completes, making them temporarily unavailable to other users. The solution will be to partition the 200, 300 and 400 series of worker nodes.
A potential problem due to potential mis-use through lack of understanding of the scheduling system can be seen. Here the submitted job has reserved 4 cores on each node yet it only runs 4 threads in total. The PBS reservation directive should closely match the mpirun arguments and machine file parameters. Here mpirun has been called with the argument "-np 4", while the PBS directive "-l nodes=srvslnhpc200:ppn=4+ srvslnhpc201:ppn=4+ srvslnhpc400:ppn=4" reserves a total of 12 cores. This is wasteful as it blocks other users from submitting jobs to idle cores. In the above example nodes 201 and 202 were not considered as they were running a separate job.