
This
week we installed five new servers bringing our core count to 208.
In 2009 we were asked to develop a five year road map of HPC at UCT. Given our inexperience we focused on the two most obvious resources, cores and disk space, and completely ignored RAM.
Over the past 18 months our researchers have taught us that large memory machines are a critical component of HPC and our next provisioning strategy will be designed around this requirement. Below is a graph of our original predicted growth path versus our actual
implementation:
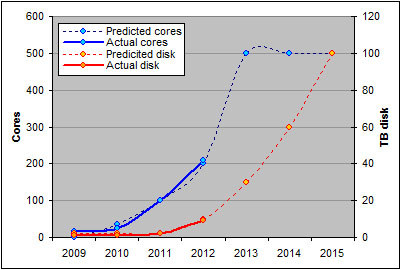
We
were able to deliver pretty much what we'd planned for as we knew that
the hardware re-provisioning strategy would make these resources
available. What was more difficult to provide was rapid storage growth,
especially storage protected by reliable backups.
Our
current disaster recovery system was spec'd for our operational
infrastructure, and not the rapid geometric growth of research data
which is an order of magnitude larger than our email, file services and
database systems combined. Solving this problem will require new
technologies such as snapshot, block level replication and NDMP. We're
hoping that our new Netapp will assist us in addressing these
challenges.
Over
the next three years we'd like to bring down the number of servers,
reduce the core growth rate and rather focus on more powerful cores with
very large RAM footprints, probably in excess of 200GB. We're
anticipating disk growth towards 50 to 75 TB, although some of this will
be data copied from other institutes and will not fall within our
disaster recovery strategy.