
The ICTS High Performance Cluster uses Torque PBS and Maui to schedule jobs. There is one head node (hex.uct.ac.za) that users connect to in order to submit jobs. The /home partition on the head node is NFS mounted (i.e. common) to all worker nodes, regardless of series. For these examples the UCTlong queue and series600 have been used as examples. Other queues utilize different series:
| Partition | Series | Description |
|---|---|---|
| uctlong | series600 | Standard HPC queue |
| GPUQ | seriesGPU | GPU card queue |
| CLOUDQ | series700 | Standard cloud based queue |
| CLOUDHMQ | series800 | High memory cloud based queue |
Basic jobs: Create a shell script with parameters similar to the one below:
#PBS -q UCTlong #PBS -l nodes=1:ppn=1:series600 #PBS -N MyRunTest-A15 /opt/exp_soft/softwareX/xyz -o /home/fred/testA15/myfile.txt
You can then submit the job by typing: qsub myscript.sh
NB1: If your data files are in a sub folder you must either reference them explicitly as in the above example or use the cd command to change to the correct sub folder.
NB2: If you wish to run more than one job at a time in the same folder you must ensure that each job’s output is directed to a different file, otherwise data files will conflict or overwrite one another. In the above example the second job’s output should be directed to myfile2.txt.
NB3: If your software prefers to use all cores on a computer then make sure that you reserve these cores. For example running on an 800 series server which has 24 cores per server change the directive line in your script as follows:
#PBS -l nodes=1:ppn=24:series800
NB4: If your software consumes more than 2GB of RAM then conserve a core for each 2GB of RAM it needs regardless of whether it can use the cores. So for a job that needs 10GB of ram:
#PBS -l nodes=1:ppn=5:series600
While the job runs on the worker node standard output and standard error (the screen output you’d see if you ran on a desktop) is written to two files, .o and .e. The worker nodes have local disk normally in the order of 50GB. If the screen output of your software fills up the worker node local disk your job will fail. It is best to ensure that your job output is directed to a file in /researchdata/fhgfs, possibly with a command line argument or the linux redirect > function. In addition it is recommended that you disable all spurious or unnecessary program output to minimize on disk space usage, particularly for long job runs.
Memory control:
Like the CPU cores memory is a limited resource, however it is not as strictly controlled as core utilization and this can lead to situations where a node can run out of memory, page swap itself to death and crash. This can be avoided by setting the ppn value to be 1/2 the amount of RAM needed in GB.
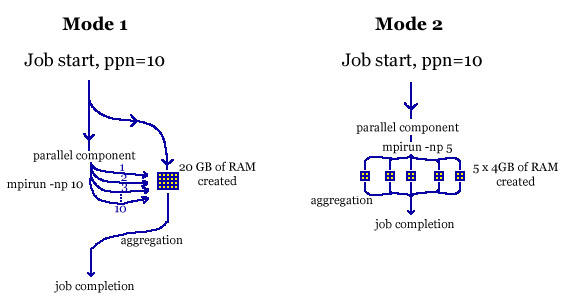
An exception or deviation to this rule applies in the following scenario; if the amount of memory that your job creates is related to the number of threads that mpirun launches then the ppn setting in your job directive will not equal the -np argument for mpirun. In other words if each thread that your job launches consumes more than 2GB of RAM, then increasing -np in accordance with ppn actually makes the problem worse. To address this you must know in advance how many GB of RAM your job will consume and set ppn to be half this, for example if your job will consume 20GB of RAM then set ppn=10. If each thread consumes 4GB of RAM then you must set -np 5. If you cannot compute the total amount of RAM your job will need from theory then you will need to investigate this empirically by running your job against small and then increasingly larger data sets.
A graphical example is shown below, where in Mode 1, a single 20GB amount of RAM is created by the job and addressed by all 10 cores or threads. In Mode 2 if each thread created a 4GB object the total memory used would be 40GB, hence ppn is set to 10 to allocate 20GB of RAM to the job by inference, but only 5 threads are launched by mpirun in order to keep the anticipated memory usage to 20GB:
Parallel jobs:
The advantage of an NFS file system is that parallel jobs write to one file system regardless of which worker node they start on. However this does mean that each job a user submits is required to start in a unique folder if the software that the job runs is not capable of specifying unique data files. As an example, user fred has a home directory /home/fred/ on the head node, and this directory is also mounted on each worker node. This means that if fred created /home/fred/myfile.txt on the head node, this file is also immediately present on each worker node. Fred now submits a job. The job initially lands on node602. OpenMPI now also starts parallel versions of this job on nodes 601 and 603 for example. Each of the three nodes writes data to /home/fred/myfile.txt If Fred now submits another job and the software that Fred is using cannot distinguish between concurrently running versions then data written to /home/fred/myfile.txt will be intermingled andor corrupted. Hence it is critical that non-concurrent capable software be launched from unique directories. If fred wants to run 3 concurrent jobs then the following need to be created: /home/fred/job1, /home/fred/job2 and /home/fred/job3. The shell script that controls the job must have a change directory command in it in order to select the correct directory. The cluster uses OpenMPI to control parallel jobs. To launch a parallel aware program one generally uses mpirun. It is critical that the shell script specifies how many servers (nodes) and CPUs will be reserved. This will inhibit other user’s jobs from trying to run on the same cores which would cause contention, slowing down both jobs. Use the #PBS directives to specify the nodes and cores. The #PBS directives can be used for other purposes too, such as giving the job a sensible name. Other #PBS directives can be found in the Torque documentation. Once a shell script is created it can be submitted to a queue by using qsub. For example, the following script, myrun.sh:
#PBS -q UCTlong
#PBS -l nodes=2:ppn=4:series600
#PBS -N MyRunTest-A15
module load mpi/openmpi-1.10.1
cd testA15
mpirun -hostfile $PBS_NODEFILE /opt/exp_soft/softwareX/xyz -o /home/fred/testA15/myfile.txt
would be submitted with the following command:
qsub myrun.sh
The shell script myrun.sh tells Torque that 2 servers and a total of 8 CPUs on each node should be reserved and that the servers should be part of the 600 series. It names the job, calls the correct directory and then invokes mpirun. PBS provides its own hostfile (or machine.file), do not use your own file. The hostfile is referenced via the environment variable $PBS_NODEFILE. As PBS and MPI are integrated it it not necessary to use the -np parameter for mpirun. The final arguments are the executable file (xyz) and then any arguments to the executable, for example myfile.txt. As another example here is a shell script that reserves 20 CPUs on the 700 series:
#PBS -q CLOUDQ #PBS -l nodes=5:ppn=4:series700 #PBS -N MyLargeRun module load mpi/openmpi-1.10.1 cd LargeRun mpirun -hostfile $PBS_NODEFILE /opt/exp_soft/softwareX/xyz -o /home/fred/LargeRun/myfile2.txt
It is important to include the series identifier to ensure that all instances of the executable behave consistently. Once the job is running a user can check the status using qstat, or by periodically looking at the HPC dashboard on the head node. To cancel a job use qdel and the job ID number. Once a job terminates all standard output will be written to a .o[jobID] file while any error messages are written to a .e[jobID] file. Other useful output should be wherever the user’s software normally directs it. It is important to not exceed the CPU and Wall times of the queue, otherwise the job will terminate. User’s can check the maximum CPU and Wall times on the dashboard. If it is suspected that these may be exceeded it would be wise to discuss this with the cluster administrators. Side note: before you can make use of OpenMPI you will need to run openmpi-selector-menu from your shell. This will give you the option of selecting the correct version of MPI to run and save this in the .mpi-selector file in your home directory.
Interactive jobs:
Submitting qsub with the -I argument effectively logs you into the worker node allowing you command line access. This is very useful for compiling, installing and debugging. Once finished type exit to stop the job and you will be returned to the head node command line interface. Please do not leave an interactive session logged in\running unnecessarily.