
Over the last week we've been testing our new Hyper-V cloud based HPC architecture. While our 600 series architecture is economical in that there are many cores per server, this forces users to share the same memory space which can lead to contention as our scheduler cannot reserve RAM, and once a job is running the only way to protect memory from a RAM hungry process is to kill it. The cloud based HPC servers can be created on the fly, carved out of whatever resources are available in the Hyper-V environment, in a variety of forms. For instance we can create twenty 4 core servers with 8GB of RAM each, then delete them and for another user create ten 4 core servers with 16GB of RAM each. The resources are thin provisioned so the system can be over subscribed, within reason. So now, instead of having to reserve 64 cores for a user who only needs 1 core but as much RAM as possible we can tailor make an environment that does not hog resources.
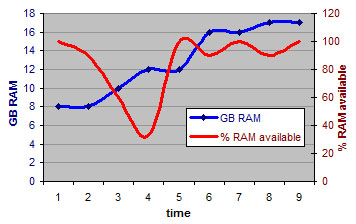
In addition to this Hyper-V has the ability to dynamically increase RAM to a virtualised operating system which, once again within reason, allows us to oversubscribe our cloud environment. Below is a simple test using a perl script to fill up the worker node's RAM. The server starts with 8GB of RAM, 100% of which is available. As the RAM is allocated the total amount of RAM on the worker node is dynamically increased up to 17GB.
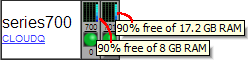
Below is a screen shot of our dashboard showing two servers which were initially identical, hpc701 now has double the RAM.
One of the disadvantages is lack of NUMA. NUMA, or non uniform memory access groups CPUs and RAM by shortest physical access path on the motherboard, ensuring fast computations. A server supporting NUMA will allow NUMA aware software to generally outperform software that cannot select the optimum chip geometry. Windows 2012 R2 supports NUMA, however this is disabled when dynamic memory allocation is enabled as the hypervisor cannot guarantee optimum geometry for future RAM expansion in a dynamic environment.
Another issue we ran into is the speed at which the RAM is allocated in that several times the worker node ran out of RAM before the hypervisor could allocate additional RAM.