Our new cluster will use cgroup to control RAM and thread allocation. One of the biggest hassles we’ve faced over the years is code not adhering to the scheduler reservation, in other words grabbing more cores and more RAM than reserved.
We have implemented cgroup on our new POC cluster and the results are very encouraging. The main culprit when it comes to over-subscription of cores is Java, especially its garbage collection routine which operates outside of the control of the scheduler. Specifying a variety of parameters (-J-XX:ActiveProcessorCount=2 -J-XX:G1ReservePercent=10 -J-XX:ParallelGCThreads=1 -J-XX:ConcGCThreads=1) is somewhat successful, but this is not always possible, especially when the calls to Java are hidden in a pipeline and the researcher cannot easily modify the command line parameters.
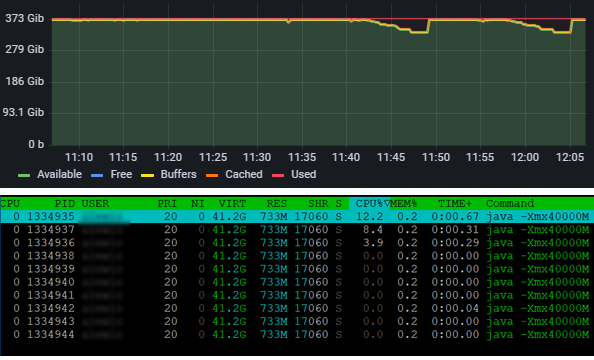
With Linux’s cgroup operating as part of the scheduler this is no longer a problem. All user space resources are compartmentalized and cannot be exceeded. Below is a particularly nasty piece of java code designed to grab as much RAM as it can and prioritize garbage collection. On our standard cluster it behaves poorly grabbing as many resources as it sees fit. On our POC cluster it adheres tightly to the single core and 40GB of RAM it has been granted, in each run the job only has access to a single core (CPU0) and is canceled as soon as it exceeds its RAM limit: